AI’s dirty little secret? Dirty data. Here’s how the Clean Data Alliance plans to fix it

The nonprofit advocacy group, which is dedicated to creating a digital economy built on the principles of clean data, is countering the rise of exploitative systems while championing a more efficient era of AI performance. Interview with Founder and CEO Michael Munson.
In certain social circles, I’m considered a “weekend warrior” of physics. I’ve read multiple books on the astro and particle varieties, and I’m known to wax on about the zeroth law of thermodynamics at a pub.
It makes me the life of the party. I think.
Sadly, a career in physics wasn’t in the cards. These days, my exploration of naturally occurring wormholes or pondering the universal mass requirements of an Alcubierre Drive is best applied when solving my wife’s mid-week insomnia.
If I’ve learned anything as a student of the hard sciences – and in my own field, the modern realm of computer science – it’s the critical role of data. This has been illuminated by the explosive growth of generative AI, as data fuels the training for LLMs across an expanding frontier of model applications.
But here’s the billion-dollar question: Is that data trustworthy?
Um… not always. We learned that the hard way when OpenAI’s swarm of bots crawled most of the internet over several years, collecting the good, the bad, and the ugly from millions of public websites.
As such, ChatGPT and the new breed of AI answer engines reflected the classic garbage-in, garbage-out conundrum, giving way to rampant misinformation and hallucinations.
Things have improved, at least in certain areas. RAG and vector-based strategies – along with the application of knowledge bases and guardrails – have enabled more targeted and reliable AI answers.
On the source side, organizations like the Data & Trust Alliance have stepped up to combat the oppressive challenge of data provenance. In 2023, the organization created standards based on associated values stored in metadata, providing details like data lineage, generation date and method, and other key dimensions. You can read my interview with Senior Policy Director Kristina Podnar if you want more deets.
These standards, which were adopted by several large enterprises, helped fortify trust – particularly for AI-related applications. Imagine focusing an analytical model on a dataset that will influence drug trials for a new type II diabetes treatment. You would want ultra-reliable data to work with, right?
It’s that kind of human example that forces us to reconcile the value of good data – clean data – and we’ve seen this play out more broadly as AI consumes the roadmap for every business. Unfortunately, the culture of Silicon Valley follows the ethos of Reid Hoffman, where we jump first (even if it’s off a cliff) and ask questions if we land safely.

Clean Data Alliance founder and CEO, Michael Munson. Source: YouTube
When I recently spoke to Michael Munson, the founder and CEO of the Clean Data Alliance – a nonprofit dedicated to establishing an infrastructure for a more fair and profitable digital economy – he explained how this hyperbolic “move-fast” mentality has ultimately damaged trust.
Said differently: Dirty data ruined the internet.
How did it happen? Well, it was almost inevitable given the power and pervasiveness of Big Tech. When Gen AI came on the scene, companies built models on whatever data they could access. It was only later that they bolted on privacy and safety controls, mostly in response to issues, misconduct, or even litigation.
It reminded me of my recent conversation with Lucy Greco about addressing accessibility from ground zero, and not as an afterthought.
When we consider the promise of AI-powered hyper-personalization as the “Holy Grail” for enterprise marketers, data has become a critical fault line. In my conversation with Michael, we touched on everything that threatens our human and personal data sovereignty – from digital ad fraud and AI hallucinations to human data rights.
The Clean Data Alliance (CDA for short), which was founded last August, is still in its first chapter. But it’s already building resources to help combat the morass of dirty data – which, according to IBM and other sources, drains $3.1 trillion from businesses through inefficiencies, inaccuracies, and compromised information and analytics.
Now, in this “Wild West” era of AI, where unproven products are hyped well before profitability at staggering levels, these issues have become more pronounced, leading to wasted time and energy, operational barriers, even revenue loss.
The Clean Data Alliance has an active Substack, and in a recent post, Michael espoused the potential for clean data – as defined by the CDA’s principles – to slash the cost of running AI models by as much as 90% while ensuring digital agency.
Can it deliver on that? Maybe.
But when we consider the existential impacts of AI on our world, we should be exploring every possible solution. And it starts by giving people control over their human data.
The internet: A dumping ground for “dirty data”
Michael is a serial entrepreneur. He’s spent the last two decades building platforms at the intersection of information technology, sponsorship marketing, and internet business model innovation. He’s been the force behind several startups, including Sponsorwise, FanTell, and Addvanz Inc., which he led from 2012 to 2024.
Currently, he’s also piloting Dāginty, a data sovereignty company designed to help replace surveillance capitalism with a collaborative, consent-based economic model.
Michael’s path to founding the Clean Data Alliance started with a practical marketing problem: How to better understand people. That exploration led him to a bigger, more troubling realization as he encountered a glut of commercial data brokers, third-party datasets, and rampant ad fraud.
“Around this time last year, I started investigating how psychographic data could be collected from people more efficiently than any of the standard or best practices of the day,” he said. “I had some experiences with commercial data, with third-party data, and also data or digital ad fraud. The lack of accuracy made me realize that there’s a lot of bad data out there. People are making decisions based on things that are not true, and that’s really problematic.”
"The lack of accuracy made me realize that there’s a lot of bad data out there. People are making decisions based on things that are not true, and that’s really problematic.”
As Michael dug deeper into areas like Personally Identifiable information (PII) and liability, the framing sharpened around the impacts of dirty data – and how it’s not just messy, it’s structurally unsafe, both ethically and economically. These included surveys shaped by bias, AI models trained on opaque inputs, and brokers building profiles with low accuracy.
“If the data is inaccurate, we’ve got a system where people who are holding this data that has PII tied to it are creating liability for themselves,” he remarked. That’s when he started viewing this as dirty data, and that clean data must be the alternative.
One of the most striking parts of our conversation was Munson’s firsthand story about a specific AI hallucination regarding an API for one of his applications. When he prompted it for details, it came back with a confident set of instructions for installing it, which he attempted to follow. As he came to discover after calling support, no such API existed.
“It made it all up,” he said. “It was crazy how much detail it gave.”
Most of us have alarming accounts of off-the-rails hallucinations. But Michael used this as a tipping point to take action against these inaccuracies. Between the lines, he also saw an opportunity to defend people’s personal data by giving them agency in a world that’s drowning in dirty data.
Defining what ‘clean data’ means
The Clean Data Alliance was built around a simple but challenging thesis: You can’t get to truly accurate, trustworthy data without putting humans in control of it. That control means embracing strong pillars for clean data:
- Verified – meaning real people
- Permissioned – based on continuous, revocable, logged consent
- Longitudinal – providing context over time
- Anonymous – where privacy is protected
Endowed with agency, individuals can then control their data, decide who can use it, and even be compensated when it creates value.
“The only way you’re going to get clean data is if you’re getting it from actual people, and it’s verified,” Michael said. “That was kind of the big revelation. We needed clean data to be produced by individual people, and the only way that people are going to do that is if they have ownership and control of their data.”
That’s contradictory to the prevailing digital economy, which, as Michael said, is surveillance-based, harvested, and extracted from you – often without choice. Data ends up being inaccurate because it’s often inferred and taken without permission. Clean data, in Michael’s view, can only emerge from consent, verification, and human agency.
As a non-profit, the CDA outlines the principles of clean data for both humans and organizations, providing a cogent balance between the interests. For companies, the mandate is around privacy and trust, enabling individuals to have respect and control.
To memorialize these facets for potential policy action, the CDA also established an “Electronic Bill of Rights” Framework (EBOR) – a human-centered framework designed to protect privacy, restore trust, and preserve freedom in a world powered by digital technology, AI, and connected devices. In many ways, it acts as an operating system for trust.
Evolving to a ‘Human Data Rights Policy’
CDA isn’t just proposing cleaner pipelines. It’s arguing for a shift in language and power, and how we talk about and structure our data relationships. For Michael, this is a mindset transformation, and he envisions a reframing of traditional privacy policies for a new era of the digital ecosystem.
“It starts with everyone being told that they own their data,” he said. “And that’s a big leap for a lot of people to make. That’s why we’re advocating for discarding the idea of calling something a ‘Privacy Policy’ and instead calling it a ‘Human Data Rights Policy,’ because that’s really what it boils down to.”
Who sets the terms for such policies? Michael believes it shouldn’t be the company or the organization forcing compliance. It should be people allowing businesses and their applications to use their data. This is especially critical for adtech platforms or data brokers that need to rebuild trust in an era of consent fatigue and rising digital sovereignty expectations.
Education, training, and a ‘Shield of Approval’
To move from theory to practice, CDA is building structures that businesses, platforms, and institutions can adopt and eventually signal to the market. The first stop? Building awareness programs and nurturing partnerships with like-minded organizations.
As Michael told me, having an educational backbone will support a concrete platform.
“Our initial focus has been on developing partnerships with organizations that we think are aligned with us, and then also developing training materials so that we can educate organizations about what clean data is and the perils of dirty data,” he explained.
Michael admitted that “data” can feel abstract and intimidating to everyday users, which is why CDA is investing so deeply in education. This includes a podcast series called Clean Data Chronicles.
“The idea there is to get people to [understand] data in a very layman’s terms kind of way, even making it fun and accessible,” he said. “We’ve found that a lot of people don’t really understand how it impacts their lives.”
A simple yet powerful tool for cultivating a more cohesive understanding is what Michael calls the “Clean Data Pyramid.” It details how raw data filters up to patterns and insight, and ultimately to the emergence of context that powers an application or recommendation.
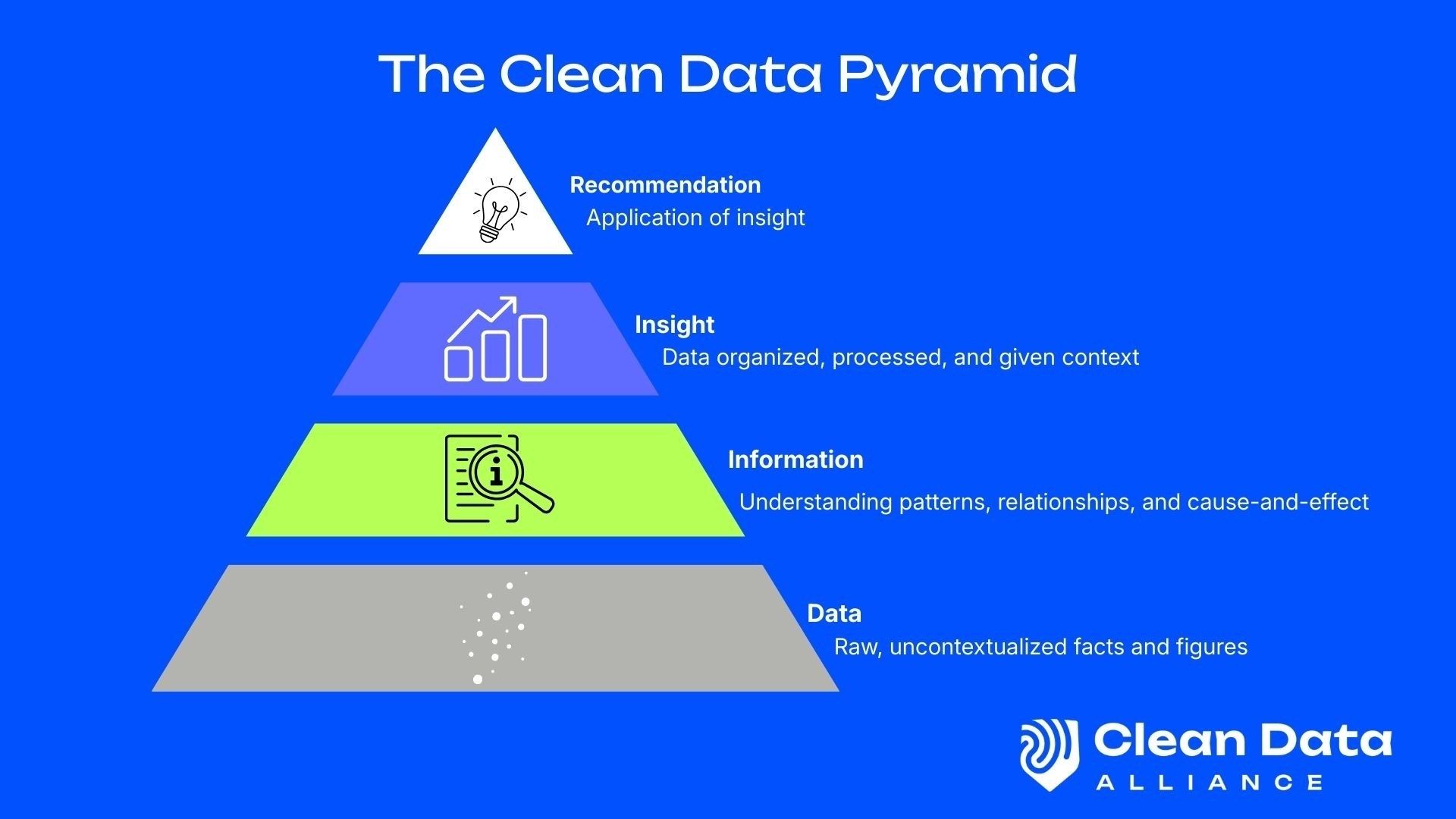
Source: The Clean Data Alliance
There’s a crucial relationship that Michael highlighted surrounding data and measurement. For example, weather shifts on a dime – so it’s constantly changing. Having a system of record (like a CMS) that can provide more context is critical to making data more valuable and actionable, especially over time. Context has become a key topic in content management, and there's a clear parallel to data and its potential to enrich it.
Michael said the CDA will soon offer certifications to organizations, crystallized by a recognizable trust mark that’s analogous to a B Corp badge. He called it a “Shield of Approval” that will place them in a fraternity of compliant businesses that have adopted the processes and best practices of the Clean Data Alliance. For customers and partners, this shield will provide verification of an organization’s clean data posture – and telegraph a heightened degree of trust.
The journey to a ‘clean data world’
While the Clean Data Alliance is still nascent, I asked Michael about the long-term goals for broader digital governance. On the legislative and policy side, he was realistic about the imbalance of power in the data economy – and that the CDA is more of the quintessential David opposing a firmly embedded Goliath.
To foment change, this movement will require more than just grassroots belief. It needs demonstrable scale. That’s why the Clean Data Alliance is targeting strategic, high-leverage goals. For example, he sees opportunities to advocate for consumers and the value of their personal data, perhaps in the form of tax exemptions. Long term, the CDA's Electronic Bill of Rights could also be a template for a legislative vision, even if they’re not leading a full-scale lobbying arm.
For CMS and DX professionals, the pursuit of clean data is paramount. Our systems don’t just manage content; they have their own pyramids of data and context. If that base is dirty, everything built on top – things like personalized experiences or product recommendations – will eventually show cracks around accuracy and integrity. This can have repercussions for brands, and uncovering these gaps is something I recently discussed with Helena Rebane at AddSearch.
For Michael, one of the most alluring attributes of a clean data-powered AI strategy rests with the dollars and cents. According to the CDA, eliminating dirty data could enhance performance and require roughly one-tenth of the compute and energy. That could transform the economics and valuations of the AI market.
Could this result in a redistribution of value as we move from resource-hungry architectures to more transparent, efficient, and compliant alternatives? It’s an ambitious vision, but one that could also usher in a new era of ethical, permission-based intelligence built on human truth.
As we continue to experiment with AI-driven data and content, Michael’s challenge to our industry is worth sitting with. More data doesn’t mean better decisions. Better data does.
If AI’s dirty little secret is that it will happily reason over dirty data, then our job – as technologists, strategists, and practitioners – is to clean things up.
Learn more at https://cleandata.world/
Upcoming Events
![]()
JoomlaDay USA 2026
April 29 - May 2, 2026 – Delray Beach, Florida
Be part of the Joomla community in one of the most iconic cities in the world! JoomlaDay USA 2026 is coming to Delray Beach, and you can join us for a dynamic event packed with insights, workshops, and networking opportunities. Learn from top Joomla experts and developers offering valuable insights and real-world solutions. Participate in interactive workshops and sessions and enhance your skills in Joomla management, development, design, and more. And connect with fellow Joomla enthusiasts, developers, and professionals from across the world. Book your seats today.
![]()
CMS Summit 26
May 12-13, 2026 – Frankfurt, Germany
The best conferences create space for honest, experience-based conversations. Not sales pitches. Not hype. Just thoughtful exchanges between people who spend their days designing, building, running, and evolving digital experiences. CMS Summit brings together people who share real stories from their work and platforms and who are interested in learning from each other on how to make things better. Over two days in Frankfurt, you can expect practitioner-led talks grounded in experience, conversations about trade-offs, constraints, and decisions, and time to compare notes with peers facing similar challenges. Space is limited for this exclusive event, so book your seats today.

Umbraco Codegarden 2026
June 10–11, 2026 – Copenhagen, DK
Join us in Copenhagen (or online) for the biggest Umbraco conference in the world – two full days of learning, genuine conversations, and the kind of inspiration that brings business leaders, developers, and digital creators together. Codegarden 2026 is packed with both business and tech content, from deep-dive workshops and advanced sessions to real-world case studies and strategy talks. You’ll leave with ideas, strategies, and knowledge you can put into practice immediately. Book your tickets today.

Open Source CMS 26
October 20–21, 2026 – Utrecht, Netherlands
Join us for the first annual edition of our prestigious international conference dedicated to making open source CMS better. This event is already being called the “missing gathering place” for the open source CMS community – an international conference with confirmed participants from Europe and North America. Be part of a friendly mix of digital leaders from notable open source CMS projects, agencies, even a few industry analysts who get together to learn, network, and talk about what really matters when it comes to creating better open source CMS projects right now and for the foreseeable future. Book your tickets today.