What I Mean to Say: A Practitioner Perspective on AI, Semantics, and Content Evolution

For practitioners in the fourth decade of content management, the evolution of content continues to fascinate. As AI transforms the landscape, will content management achieve greater capabilities together with content – or will we drift from one plateau to another?
Marc Salvatierra is a Senior Product Leader for Web Content Management and a CMS Critic Contributor. The opinions presented here are his own.
The Fourth Decade of Web Content Management
As content practitioners in the fourth decade of Web content management, tracing back to FileNet and Vignette StoryBuilder, it remains fascinating to explore how Web content has progressed from its early origins, and how it will evolve in the coming years.
In his 1974 work Computer Lib/Dream Machines, futurist and philosopher of computer science Ted Nelson described and illustrated content chunking, hypertext, and hypermaps, foretelling future related technologies like vector embeddings and knowledge graph nodes:
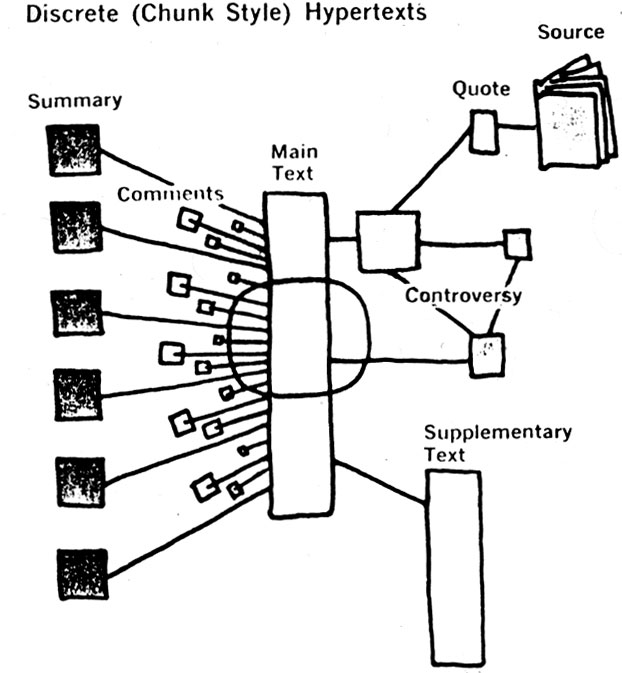
Discrete, or chunk style, hypertexts consist of separate pieces of text connected by links.
- Ted Nelson, from Computer Lib/Dream Machines (1974)
More recently, information architect Jorge Arango has highlighted the idea of Languaging Software, through which artificial intelligence will lend transformative power over language:
“Numbers are a big deal. But language is bigger. It’s foundational … Think of what easy-to-use calculating software did to the world. Now imagine a world in which we have easy-to-use languaging software.”
- Jorge Arango, from INFORMA(C)TION No. 221 (2025)
The contours of future content management and consumption are by now extensively described, involving artificial intelligence, agentic assistance, large language models, and model context protocol servers; and extending into semantics, ontologies, and knowledge graphs.
What considerations will these new and resurgent technologies introduce – and how will these tools benefit content practitioners and consumers? Will content management achieve greater capabilities together with content as it evolves – or will we drift from one plateau to another?
The Influence of Data Science Principles on Content Management
Data science principles are finding their way into the content practice, driven in part by a need for enhanced accuracy, quality, and trustworthiness of content generated with the assistance of artificial intelligence.
These principles – among them data centricity, semantics, and the shift left in data governance – will contribute fluid architecture, conceptual integrity, and engaged ownership to content management.
Data Centricity
“A data-centric enterprise is one where all application functionality is based on a single, simple, extensible data model.”
- Dave McComb, from The Data-Centric Revolution, Chapter 2: What is Data-Centric? (2019)
Dave McComb’s data-centric architecture approach, which has generally addressed the core of the enterprise, interestingly includes at its periphery the content stored in content management systems.
Data-centric architecture will shift the focus of content practitioners from the content management system to the content itself, strengthening the semantics of content within ontologies and knowledge graphs and taming the relational-database content applications that litter the Software Wasteland.
Semantics
“AI applications gain contextual understanding and decision-making ability by integrating descriptive, structural, administrative, and semantic metadata.”
- Michael Iantosca, from Content Management Considerations for Generative AI RAG (2024)
Retrieval approaches like GraphRAG rely on semantics and knowledge graphs to improve the quality of results returned by large language models. As a rough analogy to a traditional sitemap for a website, an ontology will benefit content practitioners as a map of content meaning.
Shift Left
“Shifting Left means moving ownership, accountability, quality, and governance from reactive downstream teams to proactive upstream teams.”
- Chad Sanderson, from The Shift Left Data Manifesto (2025)
For content practitioners, to shift left is to infuse content with meaning and structure from the start to avoid later disruption and cleanup. Shifting left will steer content management from primarily creating and handling text and media to include cultivating concepts and relationships among content early on.
Blending the Content Model and Org Model
“Ontology’s promise … is to make human understanding computationally usable.”
- J. Bittner, from The Shortcut Property: Where Human Semantics Meet Machine Reasoning (2025)
Consider a series of critical legal paragraphs – which financially impact several subsidiaries of a company – contained in multiple documents, created by a legal team, produced at a business meeting, held across several days, at an international office location.
Working in a CMS designed primarily for text, pages, files, and media, how would you identify and manage these dimensions semantically, then build a content experience and presentation around them, incorporating elements of law, people, money, time, and geography?
In attempting this, the content model confined to the CMS will continually bump up against the similarly isolated org model – and even other external domain models. Without torturous integrations, current content models struggle to access disparate dimensions outside the content dimension.
To apply semantics to content effectively, we will need to reshape our content and org models into a blended model – a new content+org ontology – then embed content instances in the model at appropriate semantic junctures.
Working from the ontology, we can further connect content instances to physical content – text, assets, media, or granular pieces of them – using reference pointers to locations in a database, file server, or other repository.
Gradually, as Michael Iantosca describes, I suggest that ontology- and graph-based content systems will supplant relational-database content applications as content models and content stores:
“If structured and componentized content merges with structured knowledge, why not use a graph database as the primary repository for content management and headless content delivery?”
- Michael Iantosca, from A Graph-Based Universal Component Content Management System (2025)
Content As a First-Class Semantic Citizen
Structured and well-described content will become a first-class semantic citizen, while the content management system will become a parallel concept management system. This arrangement guides and informs artificial intelligence technologies as they sift vectorized content for higher-quality results.
Semantic-Primary Content Management
Under a semantic-primary content management approach, what I mean to say as I create content will be made explicit, or will be inferred, and will be captured in the process of me saying it.
This is in contrast to first creating content, then erratically applying tags, taxonomy, and opaque relationships at a much later stage, if ever, and outside a formal semantic model.
Contactless Content Management
Content generation and assembly remain workflow-based, configuration-heavy, and typically unwieldy: filling in forms, reconciling front-end displays, tagging haphazardly, securing approvals, and resolving complex dependencies.
A byproduct of semantic-primary content management will be contactless content management, through which we “tap” and nudge content instances into semantic position within the content+org ontology, reducing authoring friction and touchpoints.
By establishing content semantics early in the content+org ontology, we can leverage the power of inference to supply metadata, establish meaningful associations, enforce gating, and handle other authoring concerns.
Inferred Information Architecture
The information architecture of semantically modelled content presented to a content consumer will be contextual, diffused and personalized.
This customized IA will extend to hierarchy, navigation, menus, labels, etc. as the scenario necessitates, reacting dynamically to inferences from the content+org ontology, user interactions, or deeper-level defaults established by a content practitioner.
The CMS Itself As Technical Debt
The CMS itself poses a risk of becoming technical debt, as today’s content management systems are not fully semantically capable. We will need semantic salvage operations to extract content and transform it to be semantically usable in other content systems or ecosystems altogether.
Future lift-and-shifts and content migrations will not be exercises in re-platforming, but of moving content within and among different semantic contexts. ETL operations will need to be able to quickly apply and update semantic contexts surrounding huge content collections, regardless of platform.
WYMIWYG: What You Model Is What You Get
As a content practitioner, if you devote time and effort to model content semantically and infuse it with quality, intent, meaning, and structure, you will be rewarded with the permutations and richness of the content that you can deliver and that you can enable consumers to assemble themselves.
Natural-Language Interactions
Assisted by artificial intelligence, content practitioners and consumers accessing a semantically sound content store will be able to conduct natural language content interactions without needing to know formal query languages, allowing iterated and even versioned content configurations.
User-Assembled Content (UAC)
Content practitioners and consumers will enjoy the power to retrieve, arrange, and mash up semantically modeled content in open-ended collages and permutations, similar to the zines of earlier decades, while incorporating content from external collections they do not directly maintain.
UAC examples:
- “Build me a product page highlighting Range Rover features for driving in snow, and show me dealers in northern Maine. You can access my Expedia account to see the hotel I will be driving to for the holidays. I’d like the product page to depict the vehicle in natural settings in that area.”
- “Compile all Acme Corporation board of directors votes held at board meetings from 2022 to 2024, and those that involve insurance premiums. Display these in a timeline with the outcomes of the votes and reference supporting documents such as claims, riders, and correspondence.”
Tool Parity Between Content Practitioners and Consumers
Content practitioners and consumers will have access to the same tool sets between them for retrieving, aggregating, and remixing public content. If a content tool is available to a content practitioner generating public content, the default will be for that tool to be available to the content consumer.
AI-Assisted Content Retrieval and Dynamic Visualization
AI-assisted content retrieval and dynamic visualization, underpinned by purpose-built ontologies and knowledge graphs, will displace centralized, templated, and rigid websites.
In Situ Content Experience and Interaction
“Once a browser starts reasoning about what you meant, it’s no longer a browser, it’s an intermediary.”
- Stuart Winter-Tear, from Everyone’s calling ChatGPT Atlas the next browser. It isn’t. (2025)
Integrating with multiple external content and data sources, the browser – not the website – will become the focal point for content experience and interaction; for retrieving content, data, and information; and for incorporating and iterating on follow-on requests.
Ad Hoc, À La Carte Content Channels
Content consumers will assemble and craft their own hyper-personalized arrangements and presentations of semantically modelled content. Surrounded by its content+org ontology, a content collection will constitute a semantic sandbox for consumers to sift through content.
Impromptu, User-Directed Content Transactions
Content consumers will likewise perform abrupt and free-ranging retrieval and navigation of semantically modelled content, bypassing corporate information architecture and thwarting practitioner efforts to steer them through curated sites.
Value Measurement of Content Transactions and Content Units
Viewing content generation and consumption as transactions, we will measure the value of any content technology by how much human friction it removes, how fast it accelerates content assembly and retrieval, how reliably it conveys meaning, and what successful outcomes it delivers for the content practitioner and content consumer alike.
In addition, we will measure the value delivered by a semantically structured content instance during an interaction. In contrast to page-level tracking, this means measuring value at the level of a discrete content fragment, such as a text phrase, image crop, or media clip. We will also measure the value of the content item’s concepts and relationships.
Content Provenance, Domain Authority, and Brand Control
Content Provenance
As artificial intelligence introduces slop, the observability of quality and reliable content will diminish. We may rely on a content blockchain for certification and traceability of authoritative content instances, immutable content versions, and content events and transactions.
URL Authority and Visibility
URLs and domains will persist as public anchors of trust, certifying the authority of content that consumers retrieve. However, while stable identifiers will continue to play a critical role, their visibility in the interface will recede, especially in devices with small viewports.
BYOP: Bring Your Own Presentation
"The Data Graphs public website runs directly on top of the Data Graphs KG app – fully content managed, edited and maintained, including imagery all in the knowledge graph
- Paul Wilton, from Data Graphs drinks its own Champagne (2023)
A knowledge graph is inherently visual: a content consumer can add a presentation layer over the knowledge graph, including elements of design, theming, layout, and user interface. These elements can be promptable, for example:
- “For this news article, use the presentation preferences in my browser settings. I like the Crisp Autumn style that I used last week to read the South China Morning Post.”
- “I prefer real estate listings to be displayed to me in sans serif font, using high-contrast colors, with no more than two columns, and text descriptions in place of images.”
Brand Control and Content Voice Control
By handing content retrieval and presentation directly to content consumers, we will inevitably see fluidity and uncertainty in AI-generated and assisted content experiences and interactions.
Maintaining control over branding and content voice will remain a significant concern. A system of enforceable defaults set by practitioners or Brand as a Service could address this concern.
CMS Consolidation or Diffusion
As content evolves, it remains unclear whether content management systems will consolidate into ambitious engineering hubs and content operating systems, or diffuse into similarly ambitious but ethereal content management ecosystems, where content lives under a semantic umbrella.
As a practitioner, I am inclined to favor the semantic-primary approach to content management and believe it will dominate. However, the range of options is not clear-cut, nor are the options mutually exclusive. Answers can hinge on contested terms of art, and hybrid outcomes are clearly possible.
Though no productized, commercial semantic-primary content management system has yet surfaced, signs of the future have appeared in proprietary form. WebMD Ignite recently announced its “wholly reimagined content ecosystem”, which employs semantic capabilities alongside artificial intelligence:
Ontologies over taxonomies
“We’re moving beyond flat tags. By modeling entities, concepts, and relationships, our CareGraph mirrors the complexity of real-world healthcare—giving AI the scaffolding it needs to interpret context and connect content with precision.”
Modular, atomic, and API-first
“Content becomes reusable ‘knowledge objects,’ each enriched with metadata, provenance, and usage rules. These can be dynamically assembled into patient journeys, microsites, or care pathways—making true personalization scalable.”
- WebMD Ignite, from From Content Management to Intelligent Content: Connected Knowledge, Connected Care (2025)
Conclusions
For practitioners in the fourth decade of content management, the evolution of content continues to fascinate and is, in some ways, arriving full circle:
- The current focus on structured content, chunking, and vector embeddings is reminiscent of Ted Nelson’s description of chunk-style hypertext in his visionary 1974 work, Dream Machines.
- After years in the wilderness, semantics, ontologies, and knowledge graphs are enjoying the spotlight as guardrails for artificial intelligence and the scaffolding for new content ecosystems.
- The reciprocal utility of AI-assisted content generation and consumption suggests a future parity in tools for both content practitioners and consumers, a nod to the Web’s collaborative roots.
- The creative capabilities, curational flexibility, and combinational possibilities offered by AI-assisted content retrieval and dynamic visualization recall the zines of earlier decades.
Surveying the content evolution, a scene emerges. As content practitioners, we will seemingly manage content from within a mesh of orchestrated agents while MCP servers hum quietly in the background.
For impatient, exploratory content consumers, page and site visits will yield to fleeting data bursts and shimmering information summaries, remixed in the browser and rendered from personalized palettes.
Past phases of content evolution have seen false starts. We lack a Preview feature to reveal how content and content management will ultimately evolve through the end of the next decade.
We do know that by drawing from data science, instilling semantics, and honing governance, what we say in our content today will still have meaning when we get there tomorrow.
References
- Why the history of content management systems still matters – Contentstack
- Computer Lib/Dream Machines – Ted Nelson
- INFORMA(C)TION No. 221 – Jorge Arango
- Content Management Considerations for Generative AI RAG – Michael Iantosca
- AI and content management – what does it all mean? – Mark Demeny
- The Data-Centric Revolution, Chapter 2: What is Data-Centric? – Dave McComb
- The Shift Left Data Manifesto – Chad Sanderson
- The Shortcut Property: Where Human Semantics Meet Machine Reasoning – J. Bittner
- A Graph-Based Universal Component Content Management System – Michael Iantosca
- A Brief History of Zines and Why You Should Make One – Alanna Stapleton
- Everyone’s calling ChatGPT Atlas the next browser. It isn’t. – Stuart Winter-Tear
- LLMs as RDF’s Long-Awaited Generic Client – Kingsley Uyi Idehen
- Data Graphs drinks its own Champagne – Paul Wilton
- SHACL Wiki knowledge graph– Veronika Heimsbakk and Ivo Velitchkov
- Sanity wants to take CMS from bottleneck to hub – Herbert Cuba Garcia
- From Content Management to Intelligent Content: Connected Knowledge, Connected Care – WebMD Ignite
Upcoming Events
![]()
Storyblok JoyConf 2025
November 4, 2025 – New York, NY
November 6, 2025 – Los Angeles, CA
Join us at JoyConf 2025, where the future of content meets the people shaping it. Built for developers, marketers, and digital innovators, this free conference goes way beyond product updates or yet another strategy playbook. It’s where you’ll get inspired, get real, and get connected – to ideas, to the community, and to what’s possible when you build joyfully. Whether you're building lightning-fast frontends or launching cross-channel campaigns, this is where content becomes connection and collaboration becomes second nature. Come for the talks. Stay for the community. Leave with joy. Save your spot.

Sitecore Symposium 2025
November 3-5, 2025 – Orlando, FL
At Sitecore Symposium, you’ll learn how to meet your customers where they are – across channels, moments, and touchpoints that didn’t exist a year ago. You’ll hear how the boldest brands in the world are transforming content into outcomes and creating experiences that are fast, relevant, and human. Join 1,500 marketers, digital leaders, and technologists in Orlando to see what’s possible when personalization scales, AI accelerates creativity, and trust becomes your competitive edge. This is the Third Wave of the Internet. And this is your moment to lead in it. Get your tickets today.

RAISE: Lifting Content into the Future with Agentic CMS
November 11, 2025 – London, UK
Join Kontent.ai at RAISE: Lifting Content into the Future with Agentic CMS, a premier free event for forward-thinking marketing and technology leaders shaping the way today’s most ambitious brands create and deliver content. Expect bold ideas, discover innovative strategies, engage with industry leaders, and gain insights that will lift your content strategy to new heights. At RAISE, you'll learn how to deliver faster, more engaging content experiences while AI does the busywork of audits, compliance, and localization with Agentic CMS, built to give you and your teams more time on creativity that matters. Reserve your seat today.

Live Webinar: Can We Ever Get Composable Without Complexity?
November 20, 2025 – 6 PM (CET) / 5 PM (GMT) / 12 PM (EST)
Composable architecture promised to simplify digital experience creation by giving organizations the flexibility to combine the technologies that met their needs. But for many enterprises, it’s done the opposite, which has led to complex integrations, spiraling costs, and what some are now referring to as composable regret. In this live conversation, Umbraco CEO Mats Persson joins Matt Garrepy, Chief Content Officer at CMS Critic, for a candid exploration of what went wrong in the first wave of composable and what needs to change. Register for the webinar.

TYPO3 Conference 2025
November 25–27, 2025 – Düsseldorf, Germany
T3CON is the premier annual event for web professionals, developers, marketers, and decision-makers. Much more than just a TYPO3-focused conference, T3CON spotlights the latest trends, innovations, and leaders shaping the future of content management, covering everything from grassroots initiatives to new technologies, strategies, and success stories. The event is designed to empower businesses and organizations with the knowledge and tools they need to thrive in the evolving digital landscape. The conference culminates in an awards ceremony celebrating the best TYPO3 projects across various industries. Get your ticket.
![]()
CMS Kickoff 2026
January 13-14, 2026 – St. Petersburg, FL
Meet industry leaders at our fourth annual CMS Kickoff – the industry's premier global CMS event. Similar to a traditional kickoff, we reflect on recent trends and share stories from the frontlines. Additionally, we will delve into the current happenings and shed light on the future. Prepare for an unparalleled in-person CMS conference experience that will equip you to move things forward. This is an exclusive event – space is limited, so secure your tickets today.